Dessa sidor presenterar hur vatten i mark, sjöar och vattendrag påverkas av klimatförändringar under 2000-talet. Visningstjänsten bygger på scenarier från flera olika regionala klimatmodeller drivna av olika globala klimatmodeller. Dessa data har sedan använts tillsammans med den hydrologisk modellen S-HYPE för att beskriva hur vatten i mark och vattendrag påverkas av klimatförändringarna. Resultaten sammanfattas till de 262 områden som visas i tjänsten.
Vid beräkningar med klimatmodeller används information om framtida förändringar i atmosfären. Klimatmodeller hanterar samverkan mellan de fysikaliska processerna i atmosfären, på marken och i havet. Klimatmodellerna har olika systematiska avvikelser i temperatur och nederbörd, vilket justeras med en så kallad biasjustering inför effektmodelleringen med den hydrologiska modellen. Klimatmodellberäkningarna är en del av de internationella forskningsprogrammen CORDEX (cordex.org) och Copernicus Climate Change Service (climate.copernicus.eu).
Den hydrologiska modellen beskriver hur vatten flödar genom mark, sjöar och vattendrag och hur mycket vatten som återförs till atmosfären genom avdunstning, eller rinner ut i haven. Detta beräknas i cirka 40 000 delavrinningsområden i Sverige, men presenteras översiktligt på 262 namngivna områden i visningstjänsten.
Klimatmodeller
För att beräkna klimatet i framtiden används klimatmodeller. Dessa innehåller 3-dimensionella representationer av atmosfären, landytan, hav, sjöar och is. I modellen är atmosfären uppdelad i ett tredimensionellt rutnät (grid) längs med jordytan och upp i luften. För att få bra resultat behöver modellen ta hänsyn till hela atmosfären, det vill säga runt hela jorden och upp i luften. Sådana modeller kallas globala klimatmodeller. I varje punkt i rutnätet beräknas tidsutvecklingen för olika meteorologiska och klimatologiska parametrar.
Klimatmodeller skapar oerhört mycket information och kräver därför mycket datorkraft vilket innebär att det tredimensionella rutnätet måste begränsas. I en global klimatmodell blir därför rutnätet ofta ganska glest, vilket leder till att detaljrikedomen blir låg på regional skala. I regionala klimatmodeller läggs rutnätet istället över ett mindre område, till exempel Europa. På så sätt kan högre detaljrikedom uppnås för ett mindre område utan att det krävs alltför mycket datorkraft.
Det som händer utanför beräkningsområdet i en regional klimatmodell styrs av resultatet från en global klimatmodell. På så sätt tar en regional klimatmodell hänsyn även till förändringar som sker utanför dess område. I denna tjänst har flera olika regionala klimatmodeller drivna av flera olika globala modeller använts. De regionala modeller som täcker Europa har en upplösning (storleken på rutorna i rutnätet över landytan) på ungefär 12,5x12,5 km.
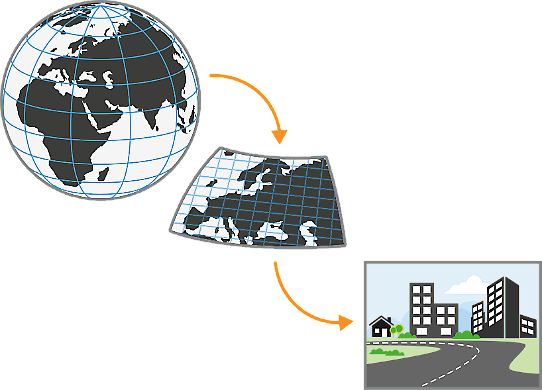
Högupplöst klimatmodellering är mycket resurskrävande, men genom så kallad nedskalning kan både mer detaljer och bättre resultat uppnås. Den högre upplösningen ger i sig fler datapunkter vilket ger mer detaljerade resultat och kan också beskriva klimatologiska processer bättre. Detta gäller framför allt korta och lokala händelser, eftersom modeller med hög upplösning beskriver dessa bättre än modeller med låg upplösning. Nederbörd i allmänhet och extrem nederbörd i synnerhet är exempel på något som förbättras med högre upplösning. Nederbörden kan variera mycket både i tid rum. Det beskrivs bättre av en modell med hög upplösning (Rummukainen, 2010; Rummukainen, 2016).
Utsläppsscenarier
Modellberäkningar av klimatet baseras på utsläppsscenarier eller strålningsscenarier. Utsläppsscenarier är antaganden om framtida utsläpp av växthusgaser. De baseras på antaganden om den framtida utvecklingen av världens ekonomi, befolkningstillväxt, globalisering, omställning till miljövänlig teknik med mera. Allt detta påverkar hur stora utsläppen av växthusgaser blir, vilket i sin tur påverkar växthuseffekten. Ett mått på hur växthuseffekten förändras i framtiden är strålningsdrivning, som mäts i effekt per kvadratmeter (W/m2). Ju mer utsläpp av växthusgaser desto mer strålningsdrivning. Sådana scenarier kallas RCP-scenarier (Representative Concentration Pathways (Moss et al., 2010; van Vuuren et al., 2011)).
I denna analys används tre scenarier:
- RCP2,6: Kraftfull klimatpolitik gör att växthusgasutsläppen kulminerar år 2020, strålningsdrivningen når 2,6 W/m² år 2100 (används i IPCC, AR5). Detta scenario är det som ligger närmast ambitionerna i Klimatavtalet från Paris.
- RCP4,5: Strategier för reducerade växthusgasutsläpp medför att strålningsdrivningen stabiliseras vid 4,5 W/m² före år 2100 (används i IPCC, AR5).
- RCP8,5: Ökande växthusgasutsläpp medför att strålningsdrivningen når 8,5 W/m² år 2100 (används i IPCC, AR5).
Klimatscenarier
Ett klimatscenario är en kombination av utsläpps- eller strålningsscenario, global klimatmodell, regional klimatmodell samt vald tidsperiod. Se tabellen i avsnittet om ensembler för mer information om de klimatmodeller som använts.
De regionala modellerna startar någon gång mellan 1951 och 1971 beroende på modell. Det kan hända att resultaten skiljer sig från observationerna redan i början. Det beror på att de globalmodeller som används inte återger dagens klimat exakt likadant i varje global modellkörning. Perioden 1971–2000 används som referens för hur klimatet förändras. Resultaten för framtiden visar alltså avvikelsen från medelvärdet för 1971–2000.
Eftersom resultatet från beräkningarna ges i ett rutnät, så kallad griddad data, så finns det svårigheter att direkt jämföra modellresultat med observationer. Observationer ger förhållandet på en viss plats, medan modellen ger medelvärdet för hela gridrutan. Beskrivningen av observerat klimat i denna tjänst baseras på griddade data och är därför lättare att jämföra med klimatmodelldata.
Referensdata
Den hydrologiska modellen är kalibrerad för att återge korrekt vattenföring när den drivs av meteorologiska data från ett referensdata set som kallas PTHBV (Johansson och Chen, 2003). PTHBV byggs upp av flera hundra dagliga observationer av nederbörd och temperatur för Sverige på ett gridnät med 4x4 km2 upplösning. PTHBV används även för biasjustering av klimatmodeller inför de hydrologiska simuleringarna.
Bias-justering
Det komplexa klimatsystemet, med många på varandra beroende processer som inte alltid är helt kända eller beskrivna i klimatmodellen, gör att det ofrånkomligen uppstår systematiska avvikelser från observerade värden. Avvikelserna kan vara olika stora för olika variabler och för olika regioner i världen. Oftast utgör dessa avvikelser inget problem för att beräkna klimatindikatorer där fokus ligger på skillnader mellan en historisk och ett framtida scenario. Men vissa indikatorer bygger på absoluta gränser, som till exempel antal dagar med frost, tropiska nätter, eller nederbörd över en viss nivå. Även effektmodellering kan påverkas av bias, till exempel vid hydrologiska beräkningar där vatten antingen lagras som snö eller rinner till åar som nederbörd beroende på eventuell bias kring fryspunkten.
En systematisk avvikelse från observationer, en bias, i klimatmodellen kan påverka dessa indikatorer så att deras uttolkning blir missvisande. För att avhjälpa sådana problem använder scenariotjänsten biasjusteringsmetoden MIdAS ((MultI-scale bias AdjuStment; Berg m.fl., 2021, 2022). MIdAS har utvecklats på SMHI och noga utvärderats med goda resultat jämfört med internationell state-of-the-art, där biasjustering tillämpas som ett nödvändigt steg inför effektmodellering. För den historiska perioden beräknas en algoritm som justerar alla modellens värden på så sätt att de överensstämmer med observationer; allt från låga värden, medelvärden, till höga värden justeras. Samma algoritm används sedan på framtida scenarier, som sedan är väl lämpade till effektmodellering och indikatorproduktion.
Hydrologisk modellering
Klimatförändringens påverkan på hydrologin beräknas med hjälp av den hydrologiska modellen S-HYPE (Lindström m.fl., 2010). S-HYPE beräknar vattenföring och andra hydrologiska parametrar baserat på matematiska representationer av lagrings- och flödesprocesser i och på marken samt i sjöar och vattendrag.
Modellens prestanda redovisas i detalj på SMHIs vattenwebb-tjänst
Den rumsliga indelningen i S-HYPE följer vattendragens avrinningsområden, och modellen beräknar vattenbalansen i cirka 40 000 delavrinningsområden i Sverige samt angränsande uppströmsområden. Modelleringen omfattar också sjöarnas och dammarnas påverkan på flödesdynamiken och även regleringsrutiner är inkluderade i modellen.
Regleringar modelleras som säsongsberoende nyckelvärden som magasins-storlek, produktionsflöden med mera. Magasinsnätverk inkluderar överledningar mellan avrinningsområden, även de parametriserade i modellen. Regleringsantaganden är oförändrade under effektmodelleringen.
Resultaten i visningstjänsten presenteras för 262 biflödesavrinningsområden (BARO), som sammanfattar avrinningsområden av hela eller delar av vattendrag, samt länsvis sammanfattade kustområden. Indelningen är en sammanvägning av detaljnivån som visningstjänstens användare förväntas behöva, och den övergripande osäkerheten i hela klimatologisk-hydrologiska modellkedjan.
Resultaten ger en överblick för den förväntade medeländringen i de presenterade hydrologiska indikatorerna över varje BARO. För indikatorer baserade på vattenföring har en för området representativ utloppspunkt valts. I reglerade vattendrag kan utloppspunkten ligga uppströms det naturliga utloppet för att bäst representera området (till exempel på grund av överledningar).
Scenarier är inte prognoser
De resultat som presenteras från beräkningar med klimatmodeller kallas klimatscenarier och är inte väderprognoser. Klimatscenarier baseras på antaganden om framtidens utsläpp och halter av växthusgaser och representerar vädrets statistiska beteende över en längre tid - det vill säga klimatet.
Indikatorer
Hydrologiska klimatindikatorer beräknas med hjälp av vanliga hydrologiska parametrar som till exempel vattenföring.
Definitioner av indikatorerna
| Namn | Definition | Enhet |
|---|---|---|
| Dagar med lågflöde | Antal dagar med vattenföring < medellågvattenföring, vilket definieras som medelvärdet av varje årets lägsta dygnsvattenföring under referensperioden (1971-2000). | dagar |
| Dagar med låg markfuktighet | Antal dagar med markfuktighet < ”medellågmarkfukt”, vilket definieras som medelvärdet av varje årets lägsta dygnsmarkfukt under referensperioden (1971-2000). | dagar |
| Effektiv nederbörd (medel) | Differensen mellan nederbörd och avdunstning från mark och växtlighet under ett dygn, i medel över perioden och det geografiska området. |
mm/månad |
| Lufttemperatur (medel) | Medeltemperaturen på 2m höjd för perioden och det geografiska området. | °C |
| Markavrinning (medel) | Medelavrinningen på marken för perioden och det geografiska området. | mm/månad |
| Markfuktighet (medel) | Medelmarkfuktigheten för perioden och det geografiska området. | Enhetslös |
| Nederbörd (medel) | Medelnederbörden för perioden och det geografiska området. | mm/dag |
| Vattenföring (medel) |
Medelvattenföringen i utloppspunkten av det geografiska området för perioden. | m3/s |
| Vattenföring (2,5,10, eller 50-års ÅT) | Årets högsta dygnsvattenföring for given återkomsttid i utloppspunkten av det geografiska området för perioden. |
m3/s |
| Snövatteninnehåll (max) | Med snövatteninnehåll menas den mängd vatten som snötäcket motsvarar i smält form. Indikatorn visar ett medelvärde av det högsta snövatteninnehållet varje år under 30-årsperioden. Värdet anges som ett medelvärde över det geografiska området. | mm |
Varför används olika referensperioder?
För att beskriva det nuvarande klimatet används den senast fullbordade 30-års normalperioden, vilken är 1991-2020. Ska äldre klimatförhållanden beskrivas kan en tidigare normalperiod användas och ska klimatets förändring studeras kan olika normalperioder jämföras.
När klimatförändringen studeras används i första hand referensnormalperioden 1961-1990 som referens, enligt WMOs riktlinjer. I vissa fall kan det vara aktuellt att använda andra normalperioder, som till exempel när förindustriell tid används som referens. Ibland används även andra tidsperioder inom klimatforskningen.
I början av 2000-talet var perioden 1961-1990 inte representativ för det nuvarande klimatet, och det var fortfarande för tidigt att gå över till nästa period, 1991-2020. Därför har till exempel IPCC ibland använt de senaste 20-30 åren som den referens som den beräknade klimatförändringen jämförs med. Ibland finns det också problem med att välja en period nära nutiden.
I många klimatsimuleringar börjar scenarierna för växthusgasutsläpp år 2006, vilket betyder att framtiden börjar redan 2006 och att åren från och med då inte representerar faktiska nivåer av växthusgaser. Det kan också finnas praktiska orsaker att 1961-1990 inte används.
Klimatmodellsimuleringar är kräver stora datorresurser. Därför händer det att simuleringar startar efter 1961 för att spara datorkraft. Då används ofta perioden 1971-2000 som en kompromiss mellan datorkraft och historisk referens.
Kunskapsbanken: Vad är normalperioder?
Om ensembler
En ensemble är en samling olika klimatscenarier (beräkningar av det framtida klimatet). Klimatscenarierna kan till exempel skilja sig åt med avseende på val av klimatmodell eller utsläpps- och strålningsscenario. Ett klimatscenario som ingår i en ensemble kallas för en medlem.
En ensemble ger en bra överblick av spridningen mellan de olika klimatscenarierna och belyser osäkerheter förknippade med att simulera det framtida klimatet. Ensemblen ger därmed ett mått på resultatens tillförlitlighet. Om många klimatscenarier ger liknande resultat ökar den relativa tillförlitligheten jämfört med om de skulle peka åt olika håll.
En typ av ensembler innehåller medlemmar som är beräknade med olika globala och/eller regionala klimatmodeller men med samma utsläpps- eller strålningsscenario. Skillnader i resultat beror då på att de olika klimatmodellerna beskriver de fysikaliska processerna i det simulerade klimatsystemet på olika sätt.
Detta visar hur osäkerheter som är förknippade med vår förståelse av hur klimatsystemet fungerar. Ibland har valet av globalmodell störst betydelse för det simulerade klimatet, till exempel när klimatet framför allt styrs av storskaliga rörelser i atmosfären. Så är fallet med temperaturen på vintern.
Nederbörden på sommaren styrs framför allt av lokal molnbildning, då är valet av regionalmodell det som är viktigast för det simulerade klimatet (Kjellström et al., 2018; Sørland et al., 2018). Det är med andra ord inte enkelt att välja vilka klimatmodeller som ska ingå i en ensemble.
En modell kan prestera bra över vissa delar av världen och sämre över andra. En annan modell kanske beskriver temperatur bra och nederbörd mindre bra. Det finns alltså ett värde i att ha stora ensembler eftersom de bättre beskriver tillförlitligheten i resultaten. I praktiken styrs valet av ensemble till stor del av hur många och vilka modellsimuleringar som är praktiskt möjliga att göra.
En annan typ av ensemble fås genom att använda en enda global klimatmodell där olika modellberäkningar görs med olika initialtillstånd vilket ger små men rimliga skillnader i modellens startvärden. Då både klimatmodeller och klimatsystemet är kaotiska till sin natur, kan en liten skillnad vid en tidpunkt leda till en betydande skillnad vid en senare tidpunkt. På detta sätt kan klimatsystemets naturliga variabilitet studeras.
I en ensemblesammanställning ger spridningen i resultaten en uppfattning om hur tillförlitliga dessa resultat är. Beroende på vilken sorts ensemble som tagits fram går det också att studera betydelsen av val av klimatmodell respektive startvärden.
I denna tjänst visas två mått på robusthet och spridning: andel modeller som ger ökning samt standardavvikelse.
Andelen modeller som ger ökning visar hur stor del av modellensemblen som ger en ökning på valt index. Om många modeller är överens om att något ökar (eller minskar) är det ett robust resultat, om modellerna är oense är det ett mindre robust resultat.
Standardavvikelsen är ett mått på spridningen mellan modeller. Även om alla modeller ger en ökning kan ökningen vara olika stor i olika modeller. Om skillnaden mellan modeller är stor är standardavvikelsen stor, om skillnaden är liten är standardavvikelsen liten. Standardavvikelsen kan också jämföras med storleken på förändringen. Om förändringen är liten jämfört med standardavvikelsen är storleken på förändringen inte robust.
Antalet modeller och scenarier som används inom en ensemble är delvis beroende på under vilken tidsperiod klimatet ska studeras. Generellt kan sägas att ju närmare i tiden (några decennier) och ju extremare situationer en fråga berör desto större är behovet av ett stort underlag av olika kombinationer av modeller och modellers starttillstånd. Om frågan istället berör ett längre tidsperspektiv (sekel) så ökar behovet av fler scenarier (som representerar olika möjliga världsutvecklingar).
Ensemblen av klimatmodeller för den hydrologiska tjänsten skiljer sig lite från den meteorologiska. Tillgängliga medel har begränsat antalet modeller som kunnat inkluderas. Därför har ett urval av sexton modeller gjorts och valet motiveras av att det är det största möjliga urvalet av kombinationer av global och regional klimatmodell som har samma tillgängliga medlemmar i alla tre utsläppsscenarierna.
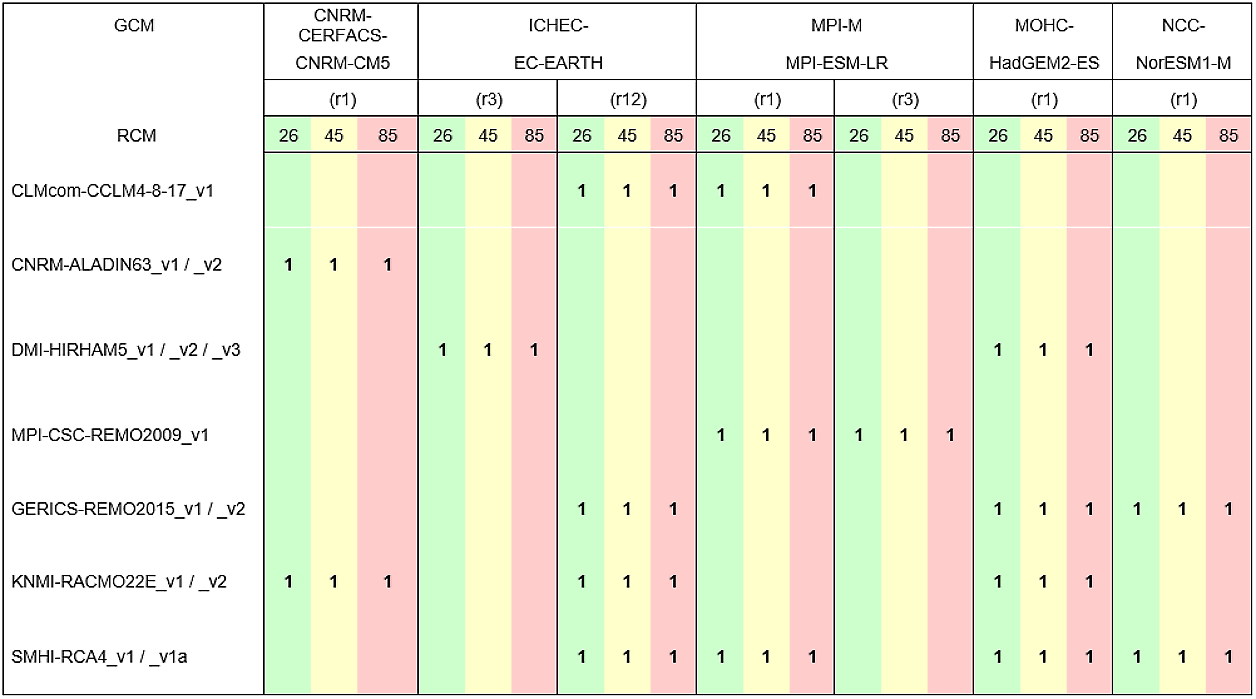
Exceltabell över klimatmodeller som används inom hydrologin (14 kB, xlsx)
Resultatens robusthet
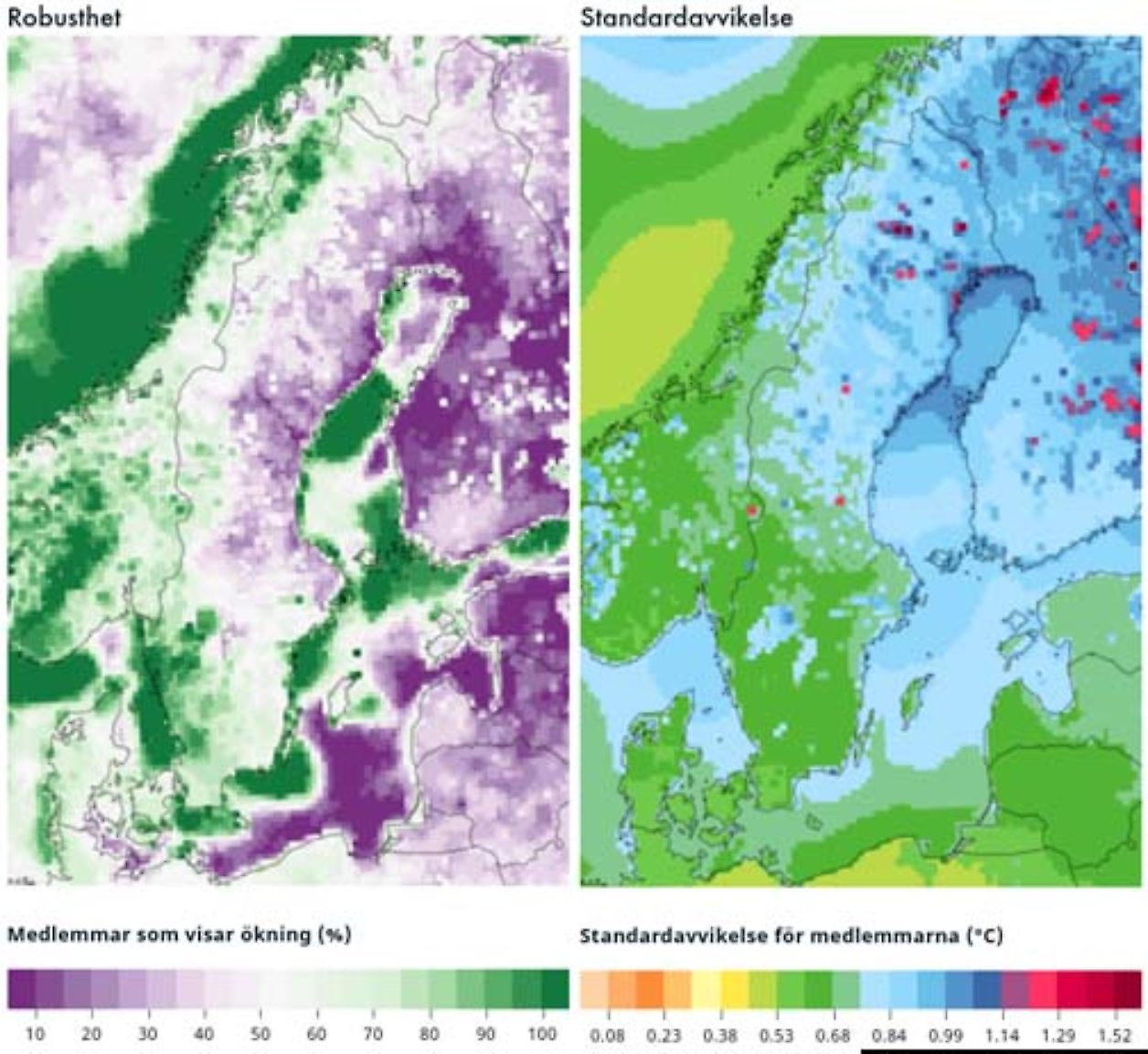
Robusthet betyder här hur säker eller osäker klimatförändringssignalen är. Eftersom resultaten baseras på flera olika simuleringar med klimatmodeller går det att göra statistiska analyser av hur robusta (dvs. tillförlitliga) resultaten är. Här används två mått på robusthet: andel modeller som ger ökning samt standardavvikelsen.
Andel modeller som ger ökning är ett mått på hur stor del av ensemblen som är överens om en förändring visar ökning eller minskning. Ju större andel av modellerna i ensemblen som pekar åt samma håll, desto mer robust resultat. Om exempelvis samtliga modeller visar att temperaturen ökar är det ett robust resultat.
Det är också ett robust resultat om inga modeller visar en ökning, det vill säga att de visar på en minskning. Om modellerna däremot fördelar sig förhållandevis jämnt mellan ökning och minskning är resultatet inte robust. Ett exempel visas i den vänstra figuren nedan. Mörkgröna färger i norra Sverige betyder att de flesta modeller är överens om en ökning och de svagare ljusa färgerna i södra Sverige visar på icke-robust ändring. I ett område i de sydöstra landskapen visar på en minskning.
Ett annat mått på resultatens robusthet är standardavvikelsen. Den visar hur stor spridningen är mellan de ingående modellerna. Om spridningen är stor är standardavvikelsen stor, om spridningen är liten är standardavviken liten. Värdet på en standardavvikelse betyder att ca 68 % av modellerna håller sig inom detta värde. I exemplet nedan är spridningen relativt liten i norra Sverige, men mer markant i söder.
Flera hydrologiska indikatorer presenteras som procentuella förändringar. Trots detta presenteras standardavvikelser eftersom de i de flest sammanhang bidrar med information om robustheten, men användaren ska vara uppmärksam på att data inte alltid är normalfördelad och standardavvikelsen kan vara missvisande.
Uppdateringar
Här ges plats för att beskriva uppdateringar som gjorts.