Huvudinnehåll
Utforska ett ämne i kunskapsbanken
Klimat
Faktapaket: Historiskt klimat
Beräkning av klimatindikatorn nederbörd
Klimatindikatorn nederbörd beräknas med hjälp av över 1 200 tidsserier. Från dessa beräknas ett medelvärde för året samt vår, sommar, höst och vinter. I artikeln beskrivs hur detta går till samt hur kvalitetsarbetet görs.
En klimatindikator visar förändringar i klimatet, till exempel hur den genomsnittliga årsnederbörden varierat över tid. För att beräkna detta behövs långa tidsserier med observationer av bra kvalitet.
Data igenomgår en gedigen granskning och om fel upptäcks justeras dessa. I sällsynta fall upptäcks direkta mätfel, men granskning görs också för att undvika att tidsserien av observationer påverkats av annat än klimatets variationer. Flytt av stationer, förändringar i närmiljön eller av mätmetod är exempel på sådant som kan komma att påverka tidsserien.
SMHIs klimatindikator för nederbörd
Klimatindikatorn nederbörd presenterar hur års- och säsongsnederbörden varierat för Sverige som helhet sedan 1880. Detta görs genom att ett medelvärde beräknas över ackumulerade års- och säsongssummorför mer än 1 200 tidsserier från stationer över hela landet.
En del av de tidsserier som ingår i klimatindikatorn innehåller observationer från en och samma plats, andra innehåller observationer från ett antal närbelägna stationer. En förutsättning för att observationer från flera stationer ska kunna användas i en och samma serie är att de är klimatologiskt lika varandra.
I diagrammen presenteras nederbördsummorna i form av avvikelsen från medelvärdet för 1961–1990. Även en utjämnad kurva, som ungefär motsvarar ett 10-års löpande medelvärde, finns med för att tydligare illustrera långtidsvariationen.
Granskning av data
Nederbördsobservationer som samlas in av SMHI och används i klimatindikatorn nederbörd granskas löpande. Ibland hittas och rättas även felaktigheter i historiska data.
Vid studier av klimatet är det också viktigt att observationer i en tidsserie inte påverkats av förändringar utöver väder och klimatets variationer. En sådan tidsserien kallas homogen.
I princip alla längre tidsserier av observationer har dock varit med om förändringar som potentiellt påverkat observationerna. Det kan exempelvis vara flytt av stationen, utbyte av instrument eller annan utrustning (exempelvis vindskydd), byte av observatör eller förändring av miljön vid eller omkring observationsplatsen såsom föränding av markanvändning, växtlighet eller byggnader. Om en sådan förändring faktiskt påverkar observationera kallas det för ett homogenitetsbrott.
Märk att observationerna i sig inte nödvändigtvis behöver anses vara behäftade med direkta mätfel varken före eller efter homogenitetsbrottet. Vid en klimatologisk analys av exempelvis en långsiktig trend, kan dock felaktiga slutsatser dras om tidsserierna som används inte är homogena, även om varje observation i sig inte är felaktig.
För SMHIs nätverk av väderstationer är en viktig sådan förändring den omfattande automatisering SMHI genomförde runt år 1995.
Luckor i tidsserier
Ibland saknas observationer för vissa tidpunkter i tidsserierna. Det kan bero på flera orsaker. Historiskt, när mätningarna enbart gjordes av observatörer kan luckor bero på semester, sjukdom eller annan frånvaro. Numera, när mätningarna till viss del är automatiserade, kan tekniska avbrott ge luckor i tidsserierna.
Observationer har även startat och upphört vid olika tillfällen. Ibland har en station upprättats i närheten av en tidigare nedlagd station och observationerna från de två platserna kan då tillåtas tillhöra samma serie. Vid dessa tillfällen kan serierna ha luckor på flera år eller till och med årtionden.
Homogenisering, luckutfyllnad och förlängning
Med hjälp av så kallad homogenisering försöker man säkerställa att tidsserien visas som om den vore uppmätt på en och samma plats, under samma förhållanden och med samma mätmetod för hela perioden. Vid klimatologiska analyser rekommenderar Världsmeteorologiska organisationen (WMO) användningen av homogeniserade data (Venema et al., 2020)
Upptäcks homogenitetsbrott justeras tidsserien genom att observerade värden före homogenitetsbrott multipliceras med faktor så att serien i slutändan motsvarar nederbörden som om den vore observerad på en och samma plats, under samma förhållanden och med samma metod för hela perioden. Beskrivning av metoden som används vid homogenisering av SMHIs nederbördsdata finns tyvärr inte ännu publicerad, men är i princip densamma som den metod som används för homogenisering av temperatur (Joelsson, 2022 samt Joelsson et al., 2022 och 2023).
Luckorna fylls i med hjälp av dels observationer från omkringliggande stationer, dels de befintliga observationerna i tidsserien i fråga. Det sker som en del av homogeniseringsprocessen.
Klimatindikatorerna kräver fullständiga serier under hela tidsperioden från 1880 för att göra medelvärdesbildningarna för varje tidpunkt jämförbara med varandra. Därför förlängs även alla serier så de täcker hela perioden med samma metod som används vid ifyllning av luckor.
Förlängning av enskilda tidsserier kan tyvärr vara behäftade med stor osäkerhet, särskilt vid långa förlängningar och i områden där stationsnätet är glest. Vid den årliga uppdatering av det homogeniserade datasetet kan därför det bli vissa förändringar även i den historiska delen av klimatindikatorn. Historiskt observerade, men nyligen digitaliserade, värden stämmer inte med nödvädighet med de tidigare beräknade värdena för motsvarande tidpunkter. Detta kan i sin tur få effekter på stationskopplingarna, på detektionen av homogenitetsbrott och på luckutfyllning av andra tidsserier. Sett över hela nätverket och över längre tidsperioder bör inte skillnaden bli avgörande för kvalitativa analyser.
Homogenitetskontroll—Exempel
Homogenisering
För att få en representativ bild av utvecklingen över tid behöver observationerna homogeniseras. Det betyder att man justerar tidsserien för förändringar som inte beror på förändringar av klimatet såsom urbanisering, förflyttning av mätplatsen, ändrade mätrutiner, förändring i närbelägen växtlighet eller byten av utrustning.
Då SMHI genomförde den omfattande automatisering av sina väderstationer runt år 1995, innebar detta ibland att nya mätplatser utsågs. Ofta utsågs dessa nya mätplatser i närheten av platser där observationer tidigare utförts. Ett sådant exempel är Pite-Rönnskär. Vide Pite-Rönnskär återupptogs nederbördsobservationerna efter nästan trettio års uppehåll tack vare införandet av de automatiska mätningarna. Se figur 1.
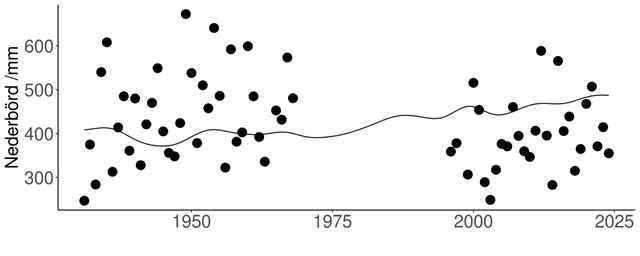
Figur 1: Exempel på ett homogenitetsbrott till följd av ersättning av en manuell nederbördsstation (Rönnskär) med en automatstation (Pite-Rönnskär A), vilket skedde 1995. De ifyllda cirklarna är de observerade värdena och den heldragna linjen är utjämnade referensvärden baserade enbart på närbelägna stationer
Byte av observationsmetod utgör dock ett potentiellt homogenitetsbrott. Detta eftersom det inte är säkert att samma verkliga nederbördsmängd resulterar i samma uppmätta nederbördsmängd om observationen utförts med en automatisk nederbördsgivare som om den utförts manuellt (Joelsson et al., 2024, Fredriksson och Ståhl, 1994). Den exakta platsen för observationerna kan också skilja sig åt. Dels beror detta på att en automatstation tar mer markyta i anspråk. Dels beror det på att automatiska vindobservationer utförs i direkt närhet till nederbördsobservationerna, vilka har medfört andra krav på platsen. Utöver det kan andra förändringar i omgivningen spela roll. Vid observationsplatsen på Pite-Rönnskär har exempelvis en del träd och buskar växt till sig sedan 60-talet.
Från figur 1 kan man se att de observerade mängderna (ifyllda cirklar) före år 1995, då automatstationen upprättades, i allmänhet är något högre än mängderna efter 1995. Detta står i motsats till den allmäna trenden i ett större området (heldragen linje) som antyder att de observerade nederbördsmängderna antagligen borde ha ökat om observationerna skett med samma metod och vid samma plats med en oförändrad närmiljö.
Homogenisering av tidsserien
Om homogenitetsbrott hittas i tidsserien kan den korrigeras så att den blir homogen. Homogenisering och luckutfyllning resulterar i figur 2.
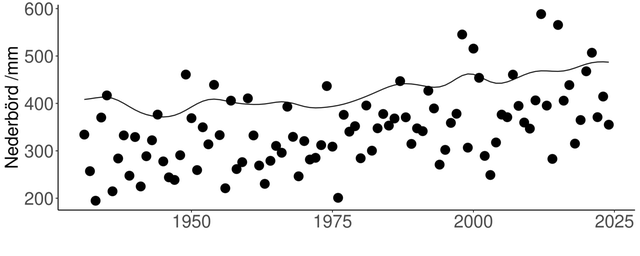
Figur 2: Motsvarande homogeniserad tidsserie för exemplet ovan
I figur 2 har tidsserien justerats så att alla värden avser det nuvarande läget av stationen. Här är detta att föredra eftersom nya observationer då kan adderas till serien utan vidare korrektioner såvida inte det sker några nya ändringar.
Skillnad mellan homogeniserade och okorrigerade observationer
I figur 3 visas ett exempel på resultatet från granskning av data. I detta exempel behandlas data till och med år 2024. Samtliga stationers observationsserier har genomgått homogenitetskontroll.
Medelvärdena baserade på homogeniserad och interpolerad data blir intressant nog inte mycket annorlunda än om okorrigerade data hade använts. Detta beror på att korrektionerna som görs för homogenitetsbrott både är positiva och negativa och att de dessutom oftast är små till storleken.
Detta illustreras i figur 3, där de homogeniserade värdena visas som gröna och brandgula staplar medan de okorrigerade värdena visas som grå staplar.
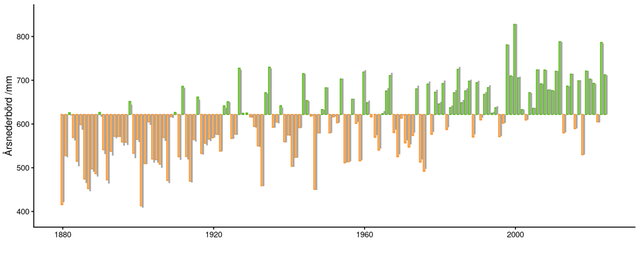
Figur 3: Klimatindikatorn årsnederbörd baserat på homogeniserade värden (röda och blå stablar) och motsvarande observerade värden (grå staplar)
Verktyg för homogenisering på SMHI
På SMHI har olika metoder använts historiskt för att homogenisera data, se Alexandersson och Moberg (1997), Moberg och Alexandersson (1997) samt Moberg och Bergström (1997).
Den senaste metoden som SMHI använder bygger på homogeniseringsverktyget HOMER (Mestre et al. 2014) och beskrivs i Joelsson (2022) och Joelsson et al. (2022 och 2024).
Som alltid är granskning av data viktigt vilket görs av experter på SMHI.
Den metod som används för att homogenisera månadstemperatur beskrivs i följande publikationer:
- Joelsson, L. M. T., Sturm, C., Södling, J., Engström, E. och Kjellström, E. (2022). Automation and evaluation of theinteractive homogenization tool HOMER. International Journal of Climatology, 42(5), 2 861–2 880. https://doi.org/10.1002/joc.7394
- Joelsson, L. M. T., Engström, E. och Kjellström, E. (2023). Homogenization of Swedish mean monthly temperature series 1860–2021. International Journal of Climatology. 43(2), 1 079–1 093
https://doi.org/10.1002/joc.7881 - Joelsson, M. (2022). Homogenisering av månadsmedeltemperatur 1860–2021. SMHI serie KLIMATOLOGI, (59).
Metoderna som historiskt har används för homogenisering beskrivs i detalj i artiklarna nedan:
- Alexandersson, H. och Moberg, A. (1997), Homogenization of Swedish Temperature data. PART I: Homogeneity Test for Linear Trends. International Journal of Climatology, 17: 25–34. doi: 10.1002/(SICI)1097-0088(199701)17:1<25::AID-JOC103>3.0.CO;2-J
- Moberg, A. och Alexandersson, H. (1997), Homogenization of Swedish Temperature data. PART II: Homogenized Gridded Air Temperature Compared with a Subset of Global Gridded Air Temperature since 1861. International Journal of Climatology, 17: 35–54. doi: 10.1002/(SICI)1097-0088(199701)17:1<35::AID-JOC104>3.0.CO;2-F
- Moberg, A. och Bergström, H. (1997), Homogenization of Swedish temperature data. Part III: the long temperature records from Uppsala and Stockholm. International Journal of Climatology, 17: 667–699. doi: 10.1002/(SICI)1097-0088(19970615)17:7<667::AID-JOC115>3.0.CO;2-J
Övriga referenser:
- Venema, V., Trewin, B., Wang, X., Szentimrey, T., Lakatos, M., Aguilar, E., ... och Rasul, G. (2020). Guidelines on Homogenization, 2020 Edition. World Meteorological Organization.
- Joelsson, M., Södling, J., Kjellström, E. och Josefsson, W. (2024). Comparison of historical and modern precipitation measurement techniques in Sweden. Idojaras-Quarterly journal of the Hungarian Meteorological Service 128(2), 195–218.
- Mestre, O., Domonkos, P., Picard, F., Auer, I., Robin, S., Lebarbier, E., Böhm, R., Aguilar, E., and Guijarro, J. A., Vertacnik, G., Klancar M., Dubuisson, B. och Stepanek P. (2013). HOMER : a homogenization software
– methods and applications. Idojaras-Quarterly journal of the Hungarian Meteorological Service 117(1), 47–67. - Fredriksson, U. och Ståhl, S. (1994). En jämförelse mellan automatiska och manuella fältmäningar av temperatur och nederbörd. SMHI serie METEOROLOGI (86).
Relaterade sidor

Klimat
Temperatur
Klimatet blir allt varmare. Sedan 1988 har alla år utom två varit varmare eller mycket varmare än genomsnittet för 1961 – 1990. Uppvärmningen beror...
Klimat
Max-/mintemperatur
Liksom för medeltemperaturen visar även maximitemperaturen och minimitemperaturen en stigande trend. Intressant att notera är att minimitemperature...
Mer i detta faktapaket
- Klimat
Historiskt klimat
Hur har temperatur och nederbörd i Sverige förändrats under lång tid? Kan man se någon förändring av salthalten i Östersjön? För att svara på de fr...
- Historiskt klimat
Beräkning av klimatindikatorn temperatur
Beräkning av klimatindikatorn temperatur Klimatindikatorn temperatur baseras på över 450 tidsserier. Utifrån dessa beräknas medelvärden för år, må...
- Historiskt klimat
Hur beräknas utjämnade långtidsmedelvärden?
Hur beräknas utjämnade långtidsmedelvärden? I diagram som illustrerar utvecklingen av exempelvis temperaturen eller nederbörden är det vanligt att...
- Historiskt klimat
Återanalyser för atmosfären
Återanalyser för atmosfären Återanalyser produceras med hjälp av observationer och en väderprognosmodell och ger användaren information för platse...
- Historiskt klimat
Återanalyser för havet
Återanalyser för havet Återanalyser produceras med hjälp av observationer och en havsmodell och ger användaren information på platser och vid tidp...



Faktapaket klimat
Alla faktapaket inom klimat
Vi har satt ihop artiklar utifrån kategorier. Allt för att du ska få ett samlat innehåll.