Om klimatscenariotjänsten: Meteorologi
Sammanfattning
Klimatscenariotjänstens meteorologiska data presenterar hur klimatet har utvecklats i Sverige till och med 2018 samt hur klimatet kan utvecklas i Sverige under 2000-talet. Visningstjänsten bygger på observationer samt scenarier från flera olika regionala klimatmodeller drivna av flera olika globala klimatmodeller, istället för som tidigare endast en regional modell. Den horisontella upplösningen i de regionala modellerna har ökat från 50 km till 12,5 km, vilket ger mer detaljerade resultat.
Filmen: Gustav Strandberg, klimatforskare på SMHI, berättar om hur du kan använda klimatscenariotjänstens delar om meteorologi.
Vid beräkningar med klimatmodeller används information om framtida förändringar i atmosfären. Klimatmodeller hanterar samverkan mellan de fysikaliska processerna i atmosfären, på marken och i havet. För vart och ett av Sveriges län har sedan resultaten från beräkningarna med klimatmodeller vidarebearbetats och omfattar perioden 1951–2100. Klimatmodellberäkningarna är en del av de internationella forskningsprogrammen CORDEX (cordex.org) och Copernicus Climate Change Service (climate.copernicus.eu).
Som jämförelsematerial presenteras även kartor som är baserade på en kombination av observationer och återanalyser för perioden 1961-2018, sammanställda i SMHI:s referensdataset. Referensdatasetet (SMHI GridClim, en optimerad kombination av stationsdata och återanalysen UERRA) innehåller bland annat dygnsmedeltemperatur, dygnets max- och mintemperatur samt dygnsnederbörd på ett rutnät över Skandinavien med 2,5 km upplösning.
Detaljerade beskrivningar
Klimatmodeller
För att beräkna klimatet i framtiden används klimatmodeller. Dessa innehåller tredimensionella representationer av atmosfären, landytan, hav, sjöar och is. I modellen är atmosfären uppdelad i ett tredimensionellt rutnät (grid) längs med jordytan och upp i luften. För att få bra resultat behöver modellen ta hänsyn till hela atmosfären, det vill säga runt hela jorden och upp i luften. Sådana modeller kallas globala klimatmodeller. I varje punkt i rutnätet beräknas tidsutvecklingen för olika meteorologiska och klimatologiska parametrar.
Klimatmodeller skapar oerhört mycket information och kräver därför mycket datorkraft vilket innebär att det tredimensionella rutnätet måste begränsas. I en global klimatmodell blir därför rutnätet ofta ganska glest, vilket leder till att detaljrikedomen blir låg på regional skala. I regionala klimatmodeller läggs rutnätet istället över ett mindre område, till exempel Europa. På så sätt kan högre detaljrikedom uppnås för ett mindre område utan att det krävs alltför mycket datorkraft.
Det som händer utanför beräkningsområdet i en regional klimatmodell styrs av resultatet från en global klimatmodell. På så sätt tar en regional klimatmodell hänsyn även till förändringar som sker utanför dess område. I denna tjänst har flera olika regionala klimatmodeller drivna av flera olika globala modeller använts. De regionala modeller som täcker Europa har en upplösning (storleken på rutorna i rutnätet över landytan) på ungefär 12,5x12,5 km.
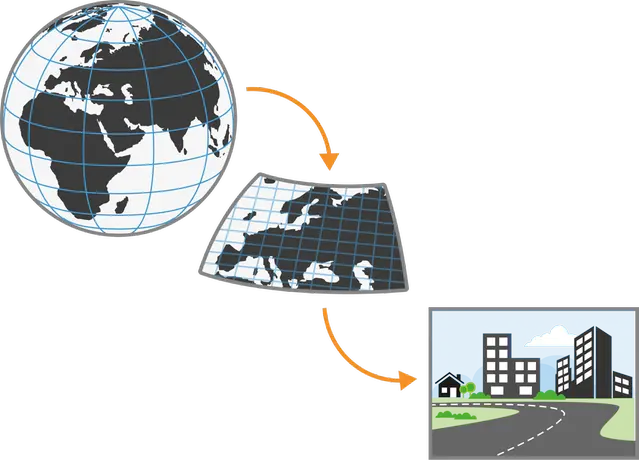
Figur. En global modell krävs för att simulera klimatet. Genom att bara modellera en del av jorden i en regional modell kan högre detaljnoggrannhet fås, men denna behöver data från en global modell. Ytterligare beräkningar och modellering kan behövas, till exempel beräkning av index eller modellering av växtlighet, urbant klimat, grundvatten.
Högupplöst klimatmodellering är mycket resurskrävande, men genom så kallad nedskalning kan både mer detaljer och bättre resultat uppnås. Den högre upplösningen ger i sig fler datapunkter vilket ger mer detaljerade resultat och kan också beskriva klimatologiska processer bättre. Detta gäller framför allt korta och lokala händelser, eftersom modeller med hög upplösning beskriver dessa bättre än modeller med låg upplösning. Nederbörd i allmänhet och extrem nederbörd i synnerhet är exempel på något som förbättras med högre upplösning. Nederbörden kan variera mycket både i tid rum. Det beskrivs bättre av en modell med hög upplösning (Rummukainen, 2010; Rummukainen, 2016).
Utsläppsscenarier
Modellberäkningar av klimatet baseras på utsläppsscenarier eller strålningsscenarier. Utsläppsscenarier är antaganden om framtida utsläpp av växthusgaser. De baseras på antaganden om den framtida utvecklingen av världens ekonomi, befolkningstillväxt, globalisering, omställning till miljövänlig teknik med mera. Allt detta påverkar hur stora utsläppen av växthusgaser blir, vilket i sin tur påverkar växthuseffekten. Ett mått på hur växthuseffekten förändras i framtiden är strålningsdrivning, som mäts i effekt per kvadratmeter (W/m²). Ju mer utsläpp av växthusgaser desto mer strålningsdrivning. Sådana scenarier kallas RCP-scenarier (Representative Concentration Pathways (Moss et al., 2010; van Vuuren et al., 2011)).
I denna analys används tre scenarier:
- RCP2,6: Kraftfull klimatpolitik gör att växthusgasutsläppen kulminerar runt år 2020, strålningsdrivningen når 2,6 W/m² år 2100 (används i IPCC, AR5). Detta scenario är det som ligger närmast ambitionerna i Klimatavtalet från Paris.
- RCP4,5: Strategier för reducerade växthusgasutsläpp medför att strålningsdrivningen når 4,5 W/m² före år 2100 (används i IPCC, AR5).
- RCP8,5: Ökande växthusgasutsläpp medför att strålningsdrivningen når 8,5 W/m² år 2100 (används i IPCC, AR5).
Klimatscenarier
Ett klimatscenario är en kombination av utsläpps- eller strålningsscenario, global klimatmodell, regional klimatmodell samt vald tidsperiod. Se tabellen i avsnittet om ensembler för mer information om de klimatmodeller som använts.
De regionala modellerna startar någon gång mellan 1951 och 1971 beroende på modell. Det kan hända att resultaten skiljer sig från observationerna redan i början. Det beror på att de globalmodeller som används inte återger dagens klimat exakt likadant i varje global modellkörning. Perioden 1971–2000 används som referens för hur klimatet förändras. Resultaten för framtiden visar alltså avvikelsen från medelvärdet för 1971–2000.
Eftersom resultatet från beräkningarna ges i ett rutnät, så kallad griddad data, så finns det svårigheter att direkt jämföra modellresultat med observationer. Observationer ger förhållandet på en viss plats, medan modellen ger medelvärdet för hela gridrutan. Beskrivningen av observerat klimat i denna tjänst baseras på griddade data och är därför lättare att jämföra med klimatmodelldata.
Scenarier är inte prognoser
De resultat som presenteras från beräkningar med klimatmodeller kallas klimatscenarier och är inte väderprognoser. Klimatscenarier baseras på antaganden om framtidens utsläpp och halter av växthusgaser och representerar vädrets statistiska beteende över en längre tid - det vill säga klimatet.
Referensdata
Förutom data från regionala klimatmodeller innehåller tjänsten även kartor baserade på en kombination av observationer och återanalyser för perioden 1961-2018, SMHI:s referensdataset för klimat (SMHI GridClim ). Dessa används i tidsdiagrammen som jämförelse till data från klimatmodellerna. Referensdatasetet innehåller en griddad sammanställning av dagliga observationer för dygnsmedeltemperatur, dygnets maximala och minimala temperatur samt dygnsnederbörd.
Dessa klimatvariabler har uppmätts vid SMHIs väderstationer över hela landet (mer än 900 stationer för temperatur och mer än 2 000 stationer för nederbörd). Utöver detta ingår observationer från Sveriges grannländer. En gedigen kvalitetskontroll exkluderar fysikaliskt orimliga värden.
För att kunna jämföra med data från klimatmodeller sammanställs stationsobservationerna till ett griddat dataset. För att kunna få fram värden även i rutor som inte innehåller någon av SMHIs observationsstationer, används en ”första gissning” från den regionala återanalysen UERRA. Återanalysen är en historisk 3D-simulering av atmosfären, med hänsyn taget till information från meteorologiska observationer, både vid marken och i högre skikt. Fördelen med att använda återanalysen som första gissning är att klimatvariabeln antar realistiska värden i områden där observationer saknas. UERRA:s återanalys nedskalas vidare från 11 km till 2,5 km horisontal upplösning.
Den ”första gissningen” kombineras med stationsdata med hjälp av statistiska metoder. Detta görs för att leverera en optimal interpolering av klimatvariabeln vid marken, men också på en högre upplösning i rummet (2,5 km), vilket minskar avvikelsen från observationer samtidigt som den bevarar ”mönstret” från återanalysen.
I SMHI:s referensdataset representeras varje parameter av medelvärdet för en ruta på 2,5 x 2,5 km, och motsvarar därför inte exakt det uppmätta värdet vid en observationspunkt. Tidsvariabiliteten i stationsdata kommer därför att vara högre än variabiliteten för motsvarande ruta i referensdatasetet. Som en biprodukt av den optimala interpolationsmetoden ovan kan ett konfidensintervall anges för rutans medelvärde.
Sammanfattning: SMHIs bedömning är att SMHI GridClim ger en realistiskt interpolering av klimatvariablerna dygnsmedeltemperatur, dygnets maximala och minimala temperatur samt dygnsnederbördsmängd på ett rutnät som sträcker sig över Skandinavien.
- Utifrån detta dataset kan ett antal klimatindikatorer beräknas.
- Samma dataset kan också användas som referens för att beräkna klimatförändring för olika parametrar i klimatprojektioner (framtida klimat).
- Datasetet kan användas som referensdata för att genomföra en bias-justering av klimatmodeller (se stycket om bias-justering).
Biasjustering
Det komplexa klimatsystemet, med många på varandra beroende processer som inte alltid är helt kända eller beskrivna i klimatmodellen, gör att det ofrånkomligen uppstår systematiska avvikelser från observerade värden. Avvikelserna kan vara olika stora för olika variabler och för olika regioner i världen.
Oftast utgör dessa avvikelser inget problem för att beräkna klimatindikatorer där fokus ligger på skillnader mellan en historisk och ett framtida scenario. Men vissa indikatorer bygger på absoluta gränser, som till exempel antal dagar med frost, tropiska nätter, eller nederbörd över en viss nivå. Även effektmodellering kan påverkas av bias, till exempel vid hydrologiska beräkningar där vatten antingen lagras som snö eller rinner till åar som nederbörd beroende på eventuell bias kring fryspunkten.
En systematisk avvikelse från observationer, en bias, i klimatmodellen kan påverka dessa indikatorer så att deras uttolkning blir missvisande. För att avhjälpa sådana problem använder scenariotjänsten biasjusteringsmetoden MIdAS ((MultI-scale bias AdjuStment; Berg m.fl., 2021, 2022). MIdAS har utvecklats på SMHI och noga utvärderats med goda resultat jämfört med internationell state-of-the-art, där biasjustering tillämpas som ett nödvändigt steg inför effektmodellering. För den historiska perioden beräknas en algoritm som justerar alla modellens värden på så sätt att de överensstämmer med observationer; allt från låga värden, medelvärden, till höga värden justeras. Samma algoritm används sedan på framtida scenarier, som sedan är väl lämpade till effektmodellering och indikatorproduktion.
Indikatorer
Förutom temperatur och nederbörd har ett antal så kallade klimatindikatorer beräknats. Indikatorer beräknas med hjälp av vanliga meteorologiska parametrar. Det kan vara antalet kalla eller varma dagar, ackumulerad nederbörd under en vecka eller längd på vegetationsperioden. Eftersom många indikatorer baseras på tröskelvärden (till exempel när temperaturen går över en viss gräns) blir de känsliga för systematiska avvikelser i klimatmodellerna. Om en modell till exempel är lite för kall kan det få stor betydelse för antalet riktigt varma dagar. Därför baseras beräkningarna av indikatorer på biasjusterade data (se stycket om biasjustering).
Definitioner av indikatorerna:
| Namn | Definition | Enhet |
|---|---|---|
| Temperatur | Dygnets medeltemperatur | °C |
| Maxtemperatur | Dygnsmaxtemperatur | °C |
| Mintemperatur | Dygnsminimitemperatur | °C |
| Nederbörd | Medelnederbörd | mm/mån |
| Temperaturens dygnsamplitud | Maxtemperatur minus mintemperatur | °C |
| Kylgraddagar | Graddagar med medeltemperatur > 20 °C | Graddagar |
| Graddagar för uppvärmning | Graddagar med medeltemperatur < 17 °C | Graddagar |
| Nollgenomgångar | Antal dygn med maxtemperatur > 0 °C och mintemperatur < 0 °C | Antal dygn |
| Frostdygn | Antal dygn med mintemperatur < 0 ºC | Antal dygn |
| Dygn med kraftig nederbörd | Antal dygn med nederbörd > 10 mm/dygn | Antal dygn |
| Dygn med extrem nederbörd | Antal dygn med nederbörd > 20 mm/dygn | Antal dygn |
| Torra dygn | Antal dygn med nederbörd < 1 mm | Antal dygn |
| Längsta torrperioden | Längsta sammanhängande period med nederbörd < 1 mm/dygn | Antal dygn |
| Vegetationsperiodens start | Det första dygnet i den första sammanhängande perioden om sex dygn där alla de sex dygnen har dygnsmedeltemperatur > 5 °C | Dagnummer |
| Vegetationsperiodens slut | Det första dygnet i den första sammanhängande perioden om sex dygn där alla de sex dygnen har dygnsmedeltemperatur < 5 °C, efter den 1 juli | Dagnummer |
| Vegetationsperiodens längd | Antalet dygn från vegetationsperiodens start till och med vegetationsperiodens slut | Antal dygn |
| Högsommardygn | Antal dygn med maxtemperatur > 25 °C | Antal dygn |
| Längsta period med högsommardygn | Längsta sammanhängande period med högsommardygn (maxtemperatur > 25 °C) | Antal dygn |
| Tropiska dygn | Antal dygn med mintemperatur > 20 °C | Antal dygn |
| Kalla dygn | Antal dygn med maxtemperatur < -7 °C | Antal dygn |
Varför används olika referensperioder?
För att beskriva det nuvarande klimatet används den senast fullbordade 30-års normalperioden, vilken är 1991-2020. Ska äldre klimatförhållanden beskrivas kan en tidigare normalperiod användas och ska klimatets förändring studeras kan olika normalperioder jämföras.
När klimatförändringen studeras används i första hand referensnormalperioden 1961-1990 som referens, enligt WMOs riktlinjer. I vissa fall kan det vara aktuellt att använda andra normalperioder, som till exempel när förindustriell tid används som referens. Ibland används även andra tidsperioder inom klimatforskningen.
I början av 2000-talet var perioden 1961-1990 inte representativ för det nuvarande klimatet, och det var fortfarande för tidigt att gå över till nästa period, 1991-2020. Därför har till exempel IPCC ibland använt de senaste 20-30 åren som den referens som den beräknade klimatförändringen jämförs med. Ibland finns det också problem med att välja en period nära nutiden. I många klimatsimuleringar börjar scenarierna för växthusgasutsläpp år 2006, vilket betyder att framtiden börjar redan 2006 och att åren från och med då inte representerar faktiska nivåer av växthusgaser.
Det kan också finnas praktiska orsaker att 1961-1990 inte används. Klimatmodellsimuleringar kräver stora datorresurser. Därför händer det att simuleringar startar efter 1961 för att spara datorkraft. Då används ofta perioden 1971-2000 som en kompromiss mellan datorkraft och historisk referens.
Kunskapsbanken: Hur beräknas normalvärden?
Beräkning av ”slutet av seklet”
Slutet av seklet benämns 2071-2100. Några modeller sträcker sig inte fram till sista december 2100. Formellt kan inte dessa användas för att beräkna ett medelvärde för 2071-2100. I praktiken är det emellertid inget problem om några modeller inte täcker hela tidsperioden; så länge de täcker minst 25 år är de representativa för perioden. Eftersom det endast är en liten del av ensemblen som saknar ett eller två år har det en marginell påverkan på ensemblemedelvärdet om 2071-2100 representeras av de år från varje modell som är tillgängliga för perioden 2071-2100, eller om perioden representeras av de sista 30 åren i varje modell. Men det är mer intuitivt om perioden bara representeras av år inom intervallet 2071-2100.
Olika referensperioder
Referensperioden kan vara olika i de olika RCP-scenarierna trots att de beskriver samma klimat. Anledningen är att ensemblerna är av olika storlek. Eftersom olika många simuleringar används blir också det beräknade medelvärdet i ensemblen olika. Avvikelserna är små och har ingen praktisk betydelse.
Vad är en ensemble?
En ensemble är en samling olika klimatscenarier (beräkningar av det framtida klimatet). Klimatscenarierna kan till exempel skilja sig åt med avseende på val av klimatmodell eller utsläpps- och strålningsscenario. Ett klimatscenario som ingår i en ensemble kallas för en medlem.
Varför används ensembler?
En ensemble ger en bra överblick av spridningen mellan de olika klimatscenarierna och belyser osäkerheter förknippade med att simulera det framtida klimatet. Ensemblen ger därmed ett mått på resultatens tillförlitlighet. Om många klimatscenarier ger liknande resultat ökar den relativa tillförlitligheten jämfört med om de skulle peka åt olika håll.
Klimatmodellens betydelse
En typ av ensembler innehåller medlemmar som är beräknade med olika globala och/eller regionala klimatmodeller men med samma utsläpps- eller strålningsscenario. Skillnader i resultat beror då på att de olika klimatmodellerna beskriver de fysikaliska processerna i det simulerade klimatsystemet på olika sätt.
Detta visar hur osäkerheter som är förknippade med vår förståelse av hur klimatsystemet fungerar. Ibland har valet av globalmodell störst betydelse för det simulerade klimatet, till exempel när klimatet framför allt styrs av storskaliga rörelser i atmosfären. Så är fallet med temperaturen på vintern.
Nederbörden på sommaren styrs framför allt av lokal molnbildning, då är valet av regionalmodell det som är viktigast för det simulerade klimatet (Kjellström et al., 2018; Sørland et al., 2018). Det är med andra ord inte enkelt att välja vilka klimatmodeller som ska ingå i en ensemble.
En modell kan prestera bra över vissa delar av världen och sämre över andra. En annan modell kanske beskriver temperatur bra och nederbörd mindre bra. Det finns alltså ett värde i att ha stora ensembler eftersom de bättre beskriver tillförlitligheten i resultaten. I praktiken styrs valet av ensemble till stor del av hur många och vilka modellsimuleringar som är praktiskt möjliga att göra.
En annan typ av ensemble fås genom att använda en enda global klimatmodell där olika modellberäkningar görs med olika initialtillstånd vilket ger små men rimliga skillnader i modellens startvärden. Då både klimatmodeller och klimatsystemet är kaotiska till sin natur, kan en liten skillnad vid en tidpunkt leda till en betydande skillnad vid en senare tidpunkt. På detta sätt kan klimatsystemets naturliga variabilitet studeras.
Tillförlitlighet kan bättre beskrivas med ensembler
I en ensemblesammanställning ger spridningen i resultaten en uppfattning om hur tillförlitliga dessa resultat är. Beroende på vilken sorts ensemble som tagits fram går det också att studera betydelsen av val av klimatmodell respektive startvärden.
I denna tjänst visas två mått på robusthet och spridning: andel modeller som ger ökning samt standardavvikelse.
Andelen modeller som ger ökning visar hur stor del av modellensemblen som ger en ökning på valt index. Om många modeller är överens om att något ökar (eller minskar) är det ett robust resultat, om modellerna är oense är det ett mindre robust resultat.
Standardavvikelsen är ett mått på spridningen mellan modeller. Även om alla modeller ger en ökning kan ökningen vara olika stor i olika modeller. Om skillnaden mellan modeller är stor är standardavvikelsen stor, om skillnaden är liten är standardavvikelsen liten. Standardavvikelsen kan också jämföras med storleken på förändringen. Om förändringen är liten jämfört med standardavvikelsen är storleken på förändringen inte robust.
Tidsperioden har betydelse
Antalet modeller och scenarier som används inom en ensemble är delvis beroende på under vilken tidsperiod klimatet ska studeras. Generellt kan sägas att ju närmare i tiden (några decennier) och ju extremare situationer en fråga berör desto större är behovet av ett stort underlag av olika kombinationer av modeller och modellers starttillstånd. Om frågan istället berör ett längre tidsperspektiv (sekel) så ökar behovet av fler scenarier (som representerar olika möjliga världsutvecklingar).
Den naturliga variabiliteten viktig i ett kort perspektiv
Utöver mänsklig påverkan på klimatet har klimatsystemet en egen naturlig variabilitet. Dessa naturliga svängningar från år till år, eller från ett årtionde till ett annat, försvårar analysen av beräknade klimatscenarier. Det gäller speciellt när förändringar i klimatet på kortare tidsskalor studeras.
År 2100 beräknas klimatförändringarna jämfört med idag vara så stora att trender är tydliga även om värdena varierar kraftigt från år till år. Klimatets naturliga variation kan med dagens kunskap inte förutsägas exakt (för till exempel ett visst datum).
Däremot kan den naturliga variabiliteten studeras genom att göra en ensemble av flera klimatscenarier utifrån ett strålningsscenario men med olika startvärden. Vid seklets slut beror osäkerheten främst av vilken global klimatmodell och vilket strålningsscenario som valts.
Modeller som används i denna tjänst
Principen är att använda så många modellsimuleringar som möjligt, eftersom mer data ger ett bättre statistiskt underlag. Det kan också vara önskvärt med ensembler som inte förlitar sig för mycket på enskilda modeller.
Då får vissa modeller oproportionerligt stor betydelse. Det kan också vara önskvärt att ensemblerna för de olika RCP:erna är något så när jämförbara. Utbudet av simuleringar för RCP8,5 är betydligt större än för de andra RCP:erna.
Det finns också modellkombinationer som bara körts för en eller två RCP:er. Eftersom vi vill ha så stora ensembler som möjligt får vi acceptera att RCP-ensemblerna inte innehåller exakt samma modeller. Globalmodeller som körts med ett fåtal regionalmodeller och för bara en RCP har valts bort för att inte bidra till skevheten mellan och inom ensembler.
Exceltabell över klimatmodeller (14 kB, xlsx) Excel, 13.5 kB.
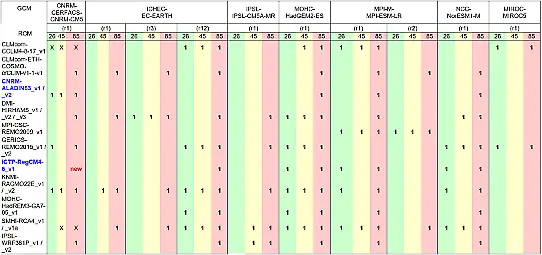 Förstora bilden
Förstora bildenModeller som ingår i ensemblen. Beteckningarna 26, 45, 85 står för scenarierna RCP2,6; RCP4,5 respektive RCP8,5. Beteckningarna r1, r3, r12 indikerar att samma globalmodell körts med olika initialvillkor.
Resultatens robusthet
Robusthet betyder här hur säker eller osäker klimatförändringssignalen är. Eftersom resultaten baseras på flera olika simuleringar med klimatmodeller går det att göra statistiska analyser av hur robusta (dvs. tillförlitliga) resultaten är. Här används två mått på robusthet: andel modeller som ger ökning samt standardavvikelsen.
Andel modeller som ger ökning är ett mått på hur stor del av ensemblen som är överens om en förändring visar ökning eller minskning. Ju större andel av modellerna i ensemblen som pekar åt samma håll, desto mer robust resultat. Om exempelvis samtliga modeller visar att temperaturen ökar är det ett robust resultat. Det är också ett robust resultat om inga modeller visar en ökning. Om modellerna däremot fördelar sig förhållandevis jämnt mellan ökning och minskning är resultatet inte robust.
Ett exempel visas i den vänstra figuren nedan. Mörkgröna färger betyder att de flesta modeller är överens om en ökning. Utanför till exempel Norges kust är andelen modeller som ger ökning 100 %; en robust signal. Lila färger betyder att de flesta modeller inte ger en ökning. I delar av Finland ger till exempel inga modeller ökning (0 % ger ökning), också det en robust signal.
Ett annat mått på resultatens robusthet är standardavvikelsen. Den visar hur stor spridningen är mellan de ingående modellerna. Om spridningen är stor är standardavvikelsen stor, om spridningen är liten är standardavviken liten. Värdet på en standardavvikelse betyder att ca 68 % av modellerna håller sig inom detta värde. I exemplet till höger nedan är spridningen förhållandevis liten i södra Sverige och större i norra Finland.
Enskilda gridpunkter avviker från det generella mönstret. Det betyder vanligtvis att en, eller ett par, modeller avviker från de flesta andra, till exempel genom att ha en starkare klimatförändringssignal. Det kan orsakas av att beskrivningen av gridrutan kan vara olika i olika modeller. I en modell kan gridrutan vara täck av vatten, i en annan av land. Effekten är tydligast längs kuster och i sjörika områden.
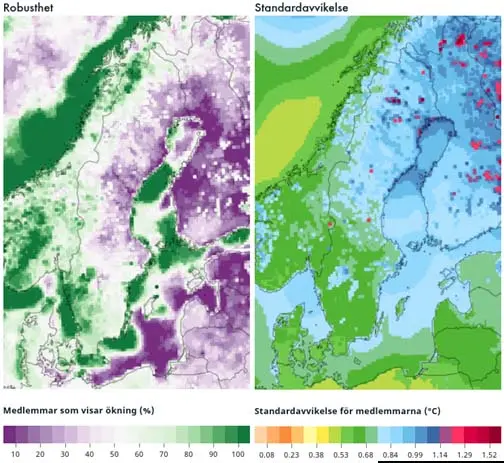 Förstora bilden
Förstora bildenFigurtext: Robusthet (vänster) är ett mått på hur många modeller i ensemblen som ger ökning, 100 % betyder att alla modeller ger ökning, 0 % betyder att inga modeller ger ökning. Standardavvikelse (höger) visar hur stor spridningen är mellan medlemmarna i ensemblen. Högre värden betyder större spridning.
Referenser
Berg, P., Bosshard, T., Yang, W., & Zimmermann, K, 2021: MIdAS version 0.1 - framtagande och utvärdering av ett nytt verktyg för biasjustering, KLIMATOLOGI, 63, SMHI.
Berg, P., Bosshard, T., Yang, W., & Zimmermann, K. 2022: MIdASv0. 2.1–MultI-scale bias AdjuStment. Geoscientific Model Development, 15(15), 6165-6180, doi: 10.5194/gmd-15-6165-2022
Kjellström, E., Nikulin, G., Strandberg, G., Christensen, O. B., Jacob, D., Keuler, K., Lenderink, G., van Meijgaard, E., Schär, C., Somot, S., Sørland, S. L., Teichmann, C., and Vautard, R., 2018: European climate change at global mean temperature increases of 1.5 and 2 °C above pre-industrial conditions as simulated by the EURO-CORDEX regional climate models, Earth Syst. Dynam., 9, 459–478, 803 https://doi.org/10.5194/esd-9-459-2018.
Moss, R. H. et al. 2010: The next generation of scenarios for climate change research and assessment. Nature, Vol 463, 11 February 2010, doi:10.1038/nature08823.
Rummukainen M., 2010: State-of-the-art with regional climate models. WIREs Clim Change 2010, 1:82–96, doi:10.1002/wcc.8.
Rummukainen, M. 2016: Added value in regional climate modeling, WIREs Clim Change 2016, 7:145–159. doi: 10.1002/wcc.378
Sørland, S. L., Schär, C., Lüthi, D. And Kjellström E., 2018: Bias patterns and climate change signals in GCM-RCM model chains, Environ. Res. Lett., 13, 074017, https://doi.org/10.1088/1748-9326/aacc7.
van Vuuren, D. P. et al., 2011: The representative concentration pathways: an overview, Climatic Change (2011) 109:5–31, DOI 10.1007/s10584-011-0148-z